TL;DR: I built a financial index that rates data sets by their markets' performance (liquidity and equality of liquidity shares). Check out the website and the minimalistic blog, or keep on reading the article.
Would you pay a stranger on the internet to buy a data set they're offering without knowing them or ever having seen the data? Tough decision! But that's precisely the type of situation Ocean Protocol users face in its newly-launched decentralized data set market [3].
I'll spare you most of the details of how it all works and say this: 2020's most transforming technology has been on-chain markets. In particular, the implementation that uniswap.org is using called automated market makers.
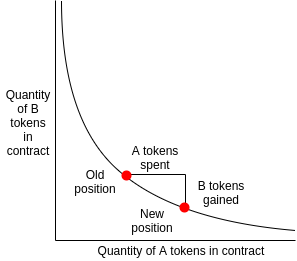
Simply put, they work by incentivizing users to pool a pair of assets at a ratio they deem as the assets' current prices. These users, I herein call them liquidity providers, e.g., pool 1 ETH and 540 USDC, so that when a buyer of either asset comes along, they can immediately trade 1 ETH for 540 USDC or 540 USDC for 1 ETH. This principle works fantastically at scale, as the pool incentivizes liquidity-providing by charging buyers and sellers a small fee, which is distributed by the pool to each liquidity provider, respectively [1].
This model has been so successful that there've been days where decentralized trading on Uniswap outperformed volumes on Coinbase! Which, of course, has lots of implications on the cryptocurrency space. I think it's no overstatement to say that automated market makers may be the killer app for crypto.
🤯 Wow, @UniswapProtocol 24hr trading volume is higher than @coinbase for the first time ever
— hayden.eth 🦄 (@haydenzadams) August 30, 2020
🦄 Uniswap: $426M
🏦 Coinbase: $348M
Hard to express with how crazy this is. pic.twitter.com/48o0xRkiUo
But there's one implication I've been particularly keen on exploring: all the openly-accessible data produced by on-chain markets. See, if you ever tried building a trading bot, you'll have noticed the terrible resolution publicly-available market data has. You might have also noticed that it's quite difficult even to find data at all. It's not by accident. Trading data is valuable.
Remember when I asked you at the beginning of this article about buying a data set from a random stranger on the internet? Well, it turns out that Ocean Protocol is now betting on the same technology that made Uniswap successful. They allow users to publish a data set, along with a fungible data token and an integrated automated market maker. Meaning, you can now buy access to a data set by purchasing tokens. These tokens get priced by liquidity providers providing a ratio of OCEAN Tokens to data tokens.
However, just because data sets are now available for sale on the market, doesn't mean you know they're valuable! After all, if ebay.com didn't have a rating system for sellers, how would you know which seller to trust?
On ebay.com, you know which seller to trust because you can see how many articles they've sold and what each buyer's experience was. It's a simple identity-based rating system.
But within the anarchistic world of cryptocurrencies, there are no working identity-based rating systems! Instead, the space is filled with sock puppets and sybils. Then, without buying a data set first, how are we supposed to know if a data set is valuable or an outright scam?
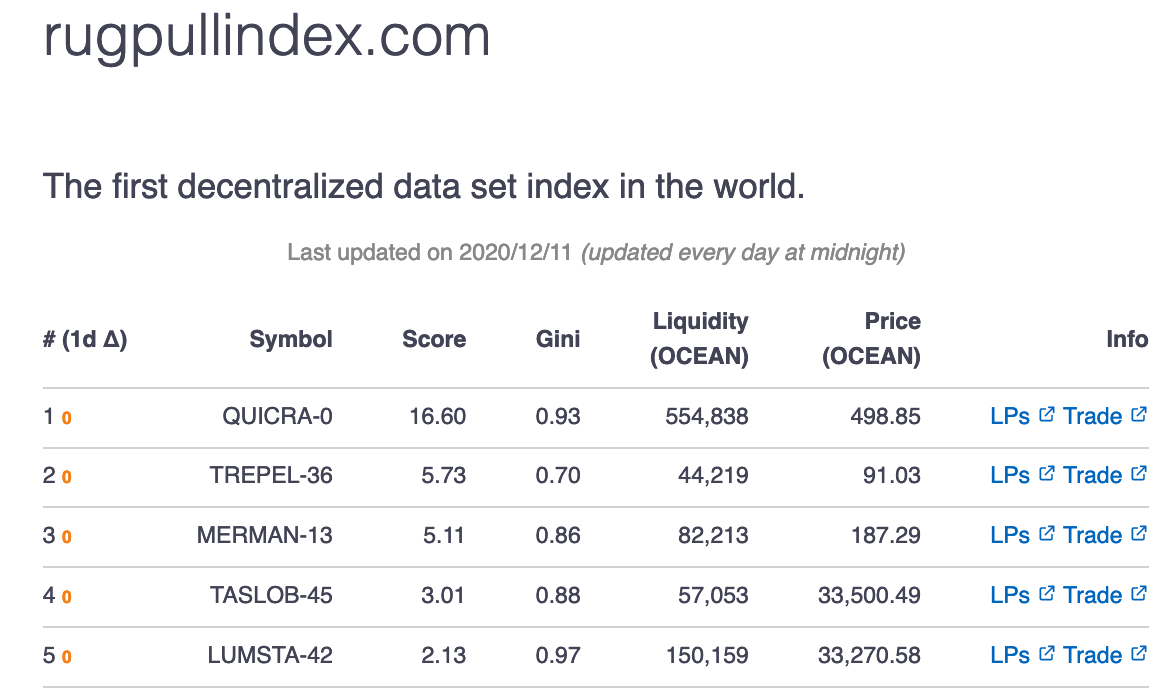
That's where rugpullindex.com comes into play. We crawl all of Ocean Protocol's data token pools daily and rate each market's liquidity provider distribution by its equality using the Gini coefficient. While ranking markets based on their liquidity is common industry-practice, calculating a Gini score for each market's liquidity provider shares isn't. The idea behind this is that the more liquidity providers with an equal share back an asset in the market, the less likely it is for a "rug pull" attack to happen (details here). By factoring in a pool's relative liquidity, it allows us to derive a score that is .
For users of rugpullindex.com, this yields a few attractive benefits:
It's a widely-known fact that index-based investment yields superior results compared to stock picking [2]. The same is true when investing in data, which makes me excited about working on this project.
I have many ideas for rugpullindex.com and not as much time as I'd like to have. However, my overarching goal is to make the ranking so reliable that I can build a smart contract-based index fund on top of it.
I think that rating assets based on their markets' performance is valuable occupation in itself. Not only within the data set market but beyond. I'm particularly interested in rating a wide range of on-chain asset markets, but I'm also thinking about rating more on-chain intellectual property markets. I'm eager to crawl more data and explore. Until then, I hope you're having fun using rugpullindex.com.
If you have questions, feedback, or business inquiries, please contact me: tim@daubenschuetz.de. If you want to follow along by building journey, please subscribe to my newsletter at the end of the page!
published 2020-12-11 by timdaub